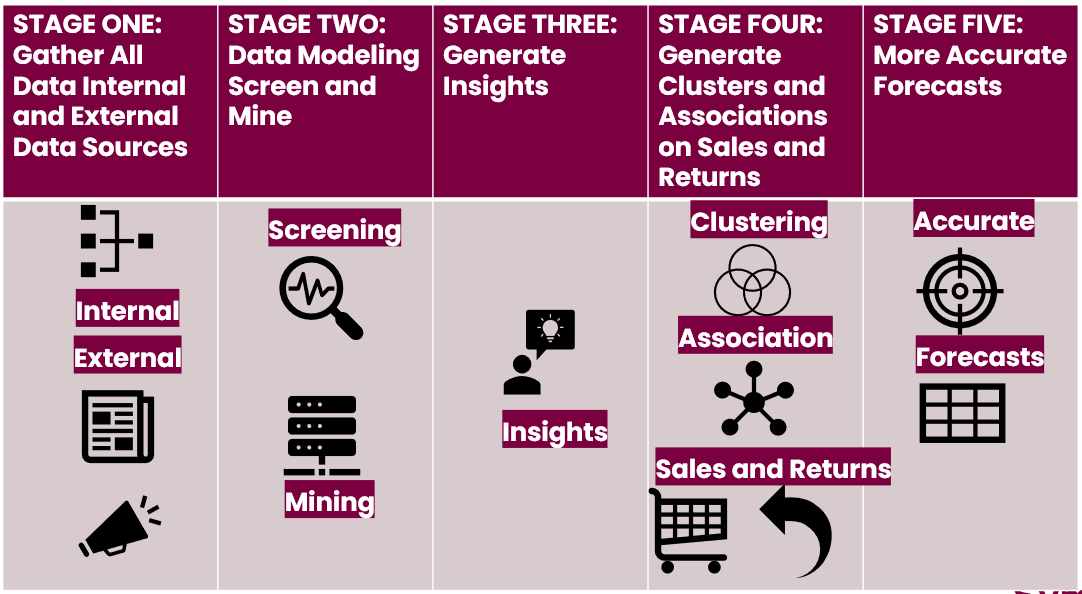
Why Data Mining
- Credit ratings/targeted marketing: Given a database of 100,000 names, which persons are the least likely to default on their credit cards?
- Identify likely responders to sales promotions
- Fraud detection
- Which types of transactions are likely to be fraudulent, given the demographics and transactional history of a particular customer?
- Customer relationship management:
Which of my customers are likely to be the most loyal, and which are most likely to leave for a competitor?
Data Mining helps extract such information
Data Mining Applications
- Banking: loan/credit card approval
- predict good customers based on old customers
- Customer relationship management:
- Identify those who are likely to leave for a competitor.
- Targeted marketing:
- Identify likely responders to promotions
- Fraud detection: telecommunications, financial transactions
- from an online stream of events identify fraudulent events
- Manufacturing and production:
- Automatically adjust knobs when process parameter changes
- Medicine: disease outcome, the effectiveness of treatments
- Analyze patient disease history: find a relationship between diseases
Molecular/Pharmaceutical: identify new drugs
- Analyze patient disease history: find a relationship between diseases
- Scientific data analysis:
- Identify new galaxies by searching for subclusters
- Web site/store design and promotion:
- Find affinity of visitors to pages and modify the layout
Data Mining- Classification
Given old data about customers and payments, predict new applicants’ loan eligibility.

Data Mining – Association Rules
Given set T of groups of items
Example: a set of item sets purchased
Goal: find all rules on item sets of the form a-->b such that: Purchase of product A --> Service B
Example: Milk --> bread
Prevalent does not equal Interesting
- Analysts already know about prevalent rules
- Interesting rules are those that deviate from prior expectation
- Mining’s payoff is in finding surprising phenomena
What makes a rule surprising?
- Does not match the prior expectation
The correlation between milk and cereal remains roughly constant over time - Cannot be trivially derived from simpler rules
Milk 10%, cereal 10%
Milk and cereal 10% … surprising
Eggs 10%
Milk, cereal, and eggs 0.1% … surprising!
Expected 1%
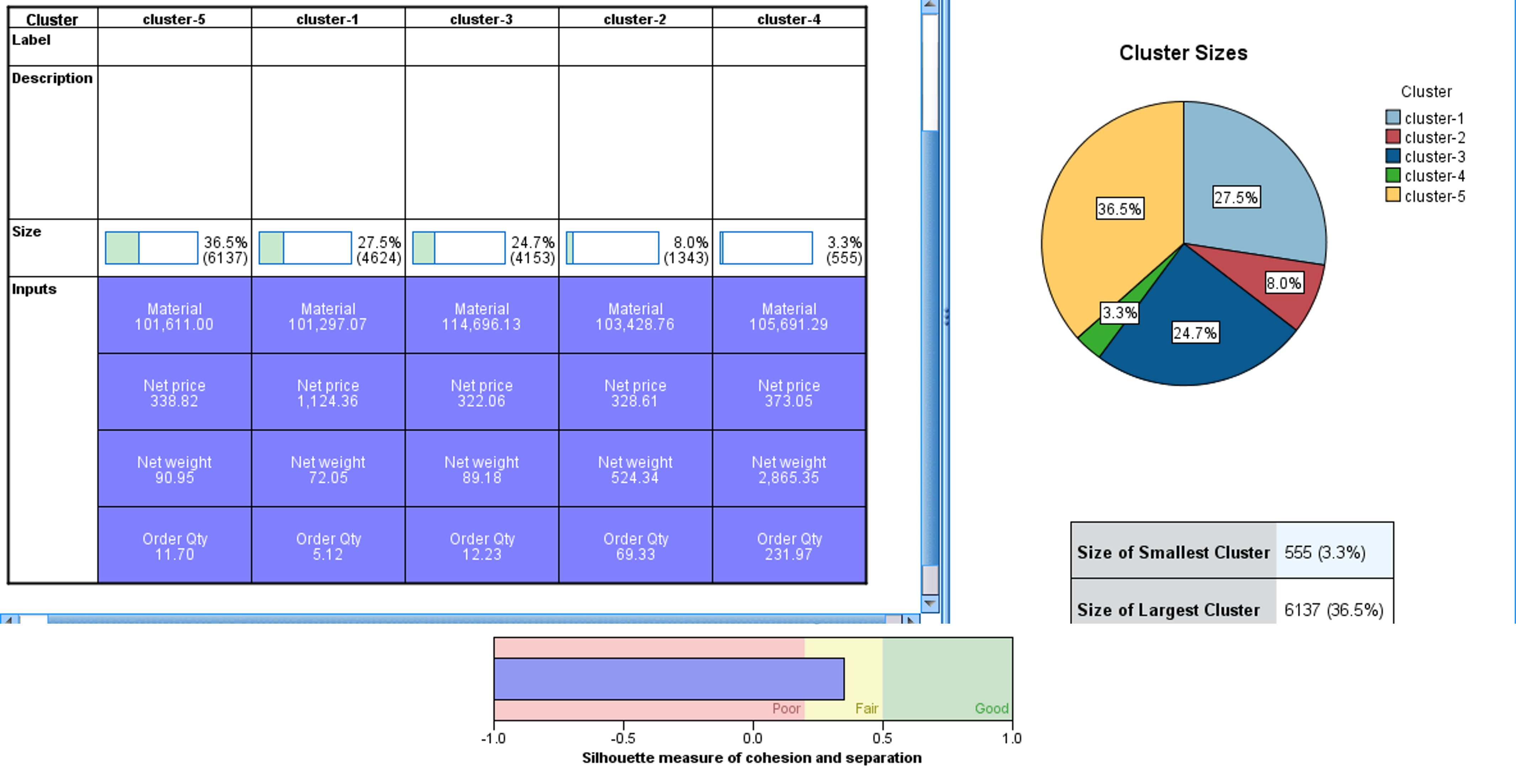
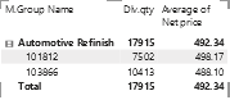
What Is Being Returned The Most?
A little bit of everything needs further investigation.
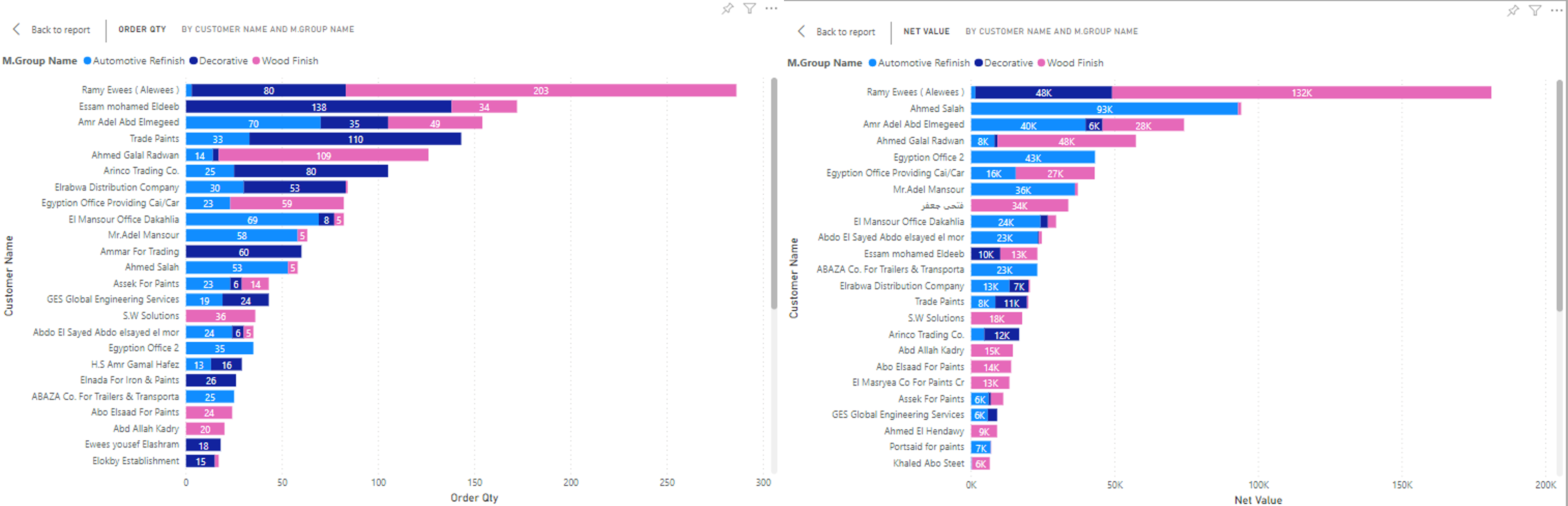
Is There a Connection?
Everything! Notice the large quantities of Wood Finish materials.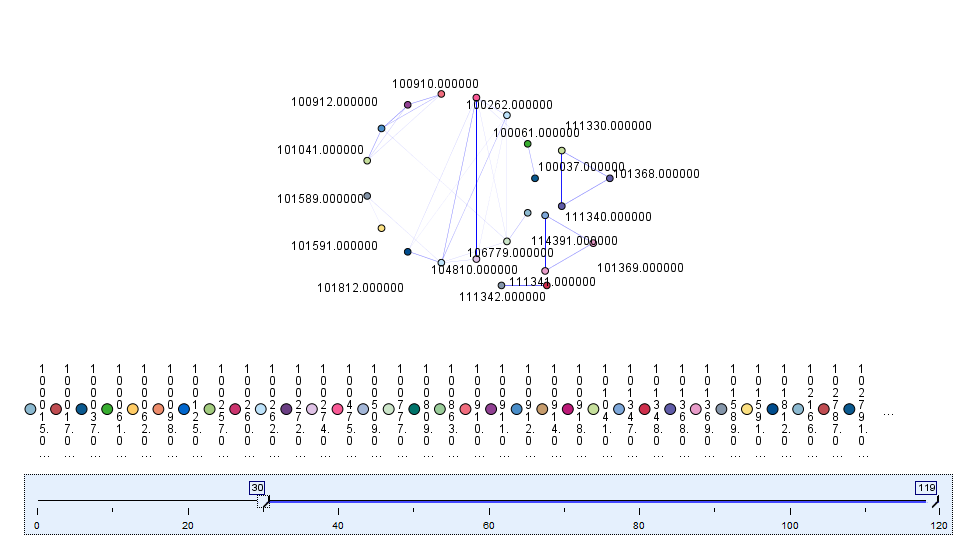
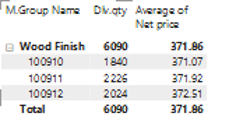
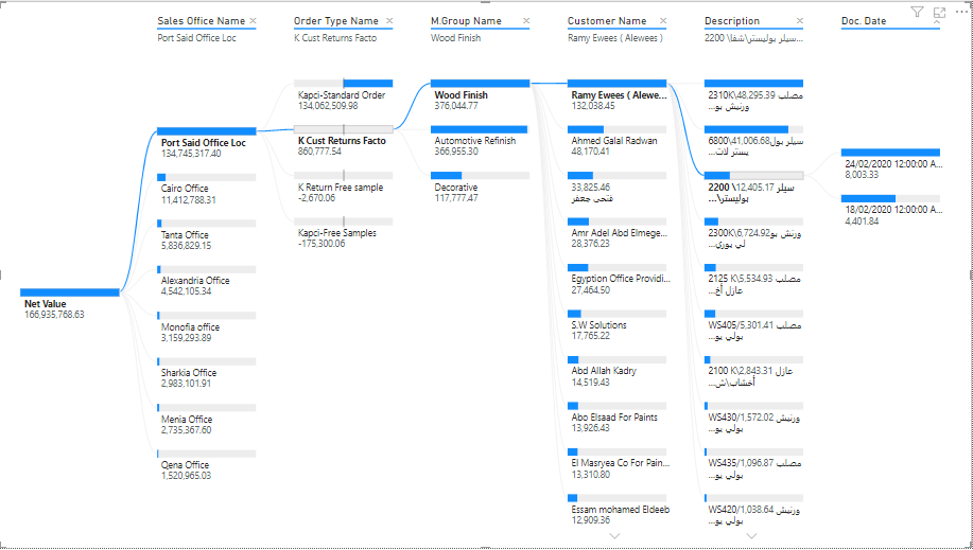
What Are Some of These Products?
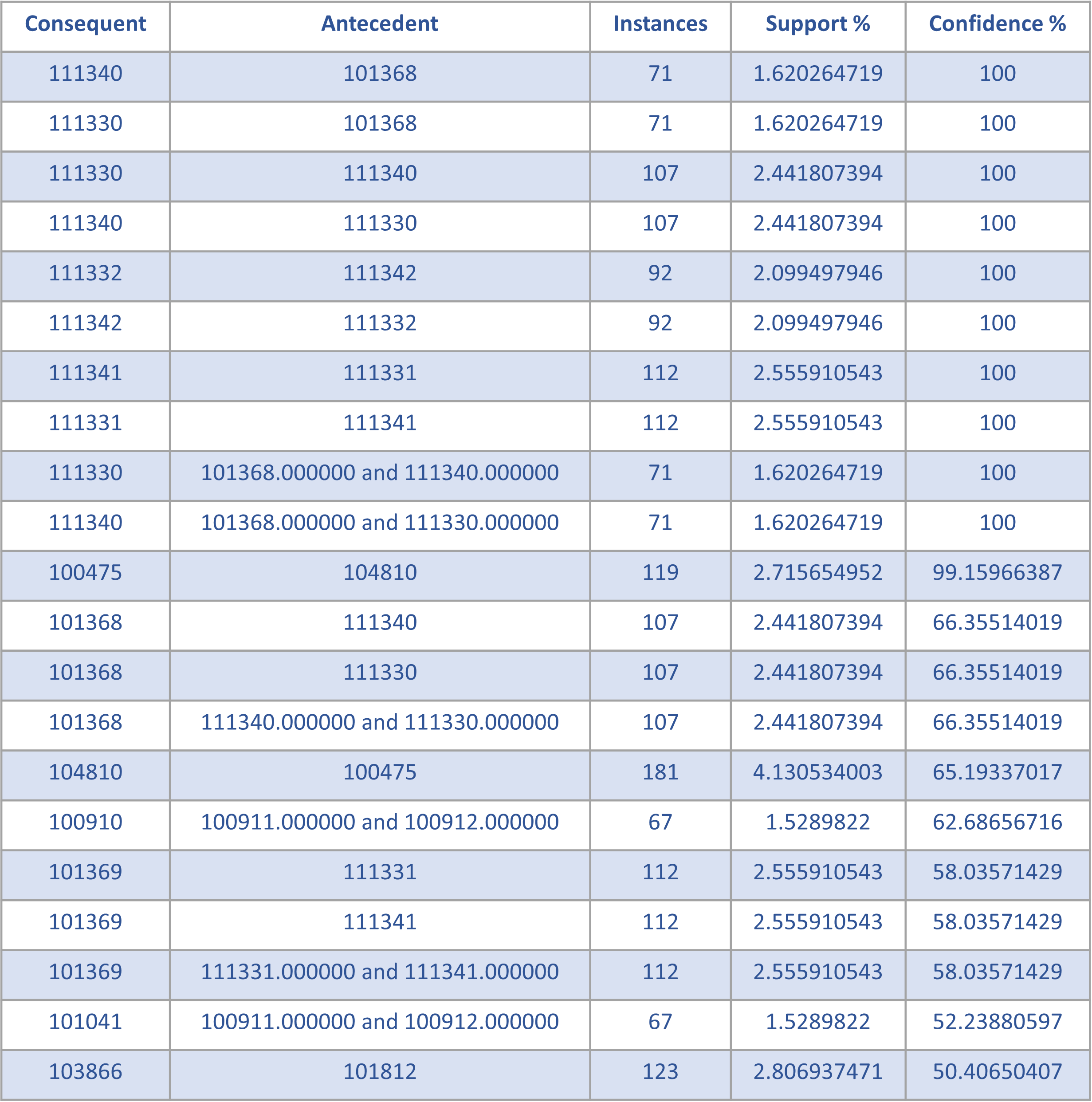
100% and more than 70 times
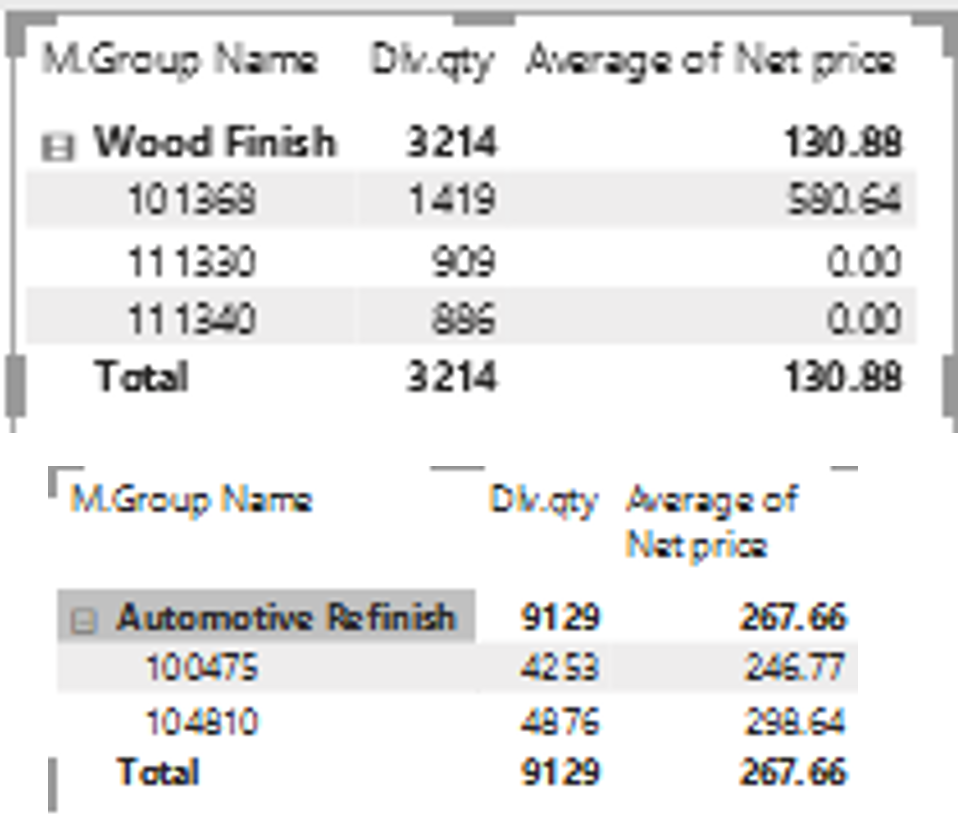
More than 60% and more than 65 times
More than 50% and more than 100 times
Decomposition Tree, showing returns multiple times, why?
Data Mining – Clustering
- Unsupervised learning when old data with class labels is not available e.g. when introducing a new product.
- Group/cluster existing customers based on time series of payment history such that similar customers in the same cluster.
Applications
- Customer segmentation e.g. for targeted marketing
- Group/cluster existing customers based on time series of payment history such that similar customers in the same cluster.
- Identify micro-markets and develop policies for each
- Collaborative filtering
- Group based on common items purchased
- Group based on common items purchased
Application Example